
https://arxiv.org/abs/2004.09388
Arxivにしかないので信頼度はある程度差し置いたほうがいい。
Introduction
この論文では、一貫性を保つようなmixupを用いたData Augmentation手法を開発。class priorの知識不要で、Uの中から信頼できるNを見つけ出してそれでMixupをするらしい。
問題設定
- データはであり、Ground TruthがならPositiveで、ならNegative。
- 実際に与えられるのはではなく、。0ならばラベルなしで、1ならばラベルがPである。
- サンプリングはCase-control(2 set)であり、Class Priorはである。
- Uはの混合分布である。
- 識別器はでlogitを出力。これをcalibrationするのはsigmoid関数の。
- Mix-upとは、の値を取り出して、以下のようにサンプル値とラベルも合成する手法で、以下の等式が成り立つだろうという期待。
Method
PU LearningにMixupする
各Minibatchとして、が渡される。
ラベルはこのデータ(目的関数でPとN、U同士などがある)に対して、識別器のパラメタの移動平均を用いた識別器の出力。
このようにData Augmentationしたを得る。
信頼できるNegative例の抽出
先ほどの前提は、ある程度正しい識別ができるということ。
これをするには、Semi-supervised Learningで、ある程度信頼できるNを選んて、PN Learningで事前に訓練する必要がある。
この研究では以下の3種類の信頼できるNの選び方を考えた。
- Rand: ランダムに選ぶ。
- Dist: 与えられたPデータからの平均距離が最も遠い順に選ぶ。
- NTC: 事前にPU Learningの識別器を訓練し、それでNである可能性が非常に高いデータを選ぶ。
例えばNTCを使うなら、PU識別器を訓練→信頼できるNを選ぶ→選んだNでPNで訓練→ある程度訓練して信頼できたら、PUでUをmixupしながら訓練という非常に手間かかることになる。
アルゴリズム
流れとしては、以下のようになる。
- 先ほどの提案した手法などで、信頼できるNを選ぶ。
- Semi-supervised Learningを用いて、信頼できるNと与えられたPである程度学習する。
- UをmixupしながらPU Learningする。
この時、ステップ3の損失は以下のように設計する。
: 与えられたPと信頼できるNでmixupして2乗損失で計算。
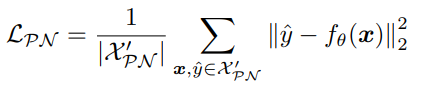
: U同士でmixupして2乗損失で計算。
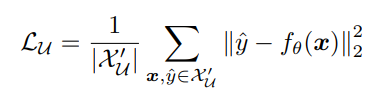
: PとUについて、 📄![]() 2017-NIPS-[nnPU] Positive-Unlabeled Learning with Non-Negative Risk Estimator と似ているが違うメカニズム(不偏推定量なんて考えていない)を用いて、clippingを使うことで過学習を防いでいる。はハイパラである。はここではという意味。小さくても0にする。
2017-NIPS-[nnPU] Positive-Unlabeled Learning with Non-Negative Risk Estimator と似ているが違うメカニズム(不偏推定量なんて考えていない)を用いて、clippingを使うことで過学習を防いでいる。はハイパラである。はここではという意味。小さくても0にする。
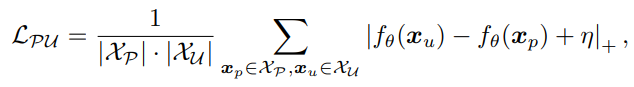
役割としては、はmixupによる正則化項、最後のは本体ということ。
Experiments
- MNIST, CIFAR10で実験。
- は必要。